데이터를 처리하다보면 범주형 자료를 수치형 자료로 바꾸어야할 필요성이 많습니다. 이러한 변환을 인코딩이라고 하는데, 다양한 목적과 자료의 특징에 맞추어 올바르게 인코딩한 범주형 자료는 모델의 퍼포먼스와 효율에 상당한 영향을 끼칩니다. 특히 최근 각광받는 머신러닝과 딥러닝에서 범주형 자료에 대한 인코딩은 필수적입니다. 그러나 인코딩은 생각만큼 단순하지 않습니다. One-Hot-Encoding/ Ordinal-Encoding/ Label Encoding/ Target Encoding… 등 종류도 다양할 뿐더러, 비슷한 인코딩도 library에 따라 크고작은 차이가 있습니다. 인코딩 특집 글에서는 자주 쓰이고, 중요한 인코딩 방식들을 소개합니다.
OneHotEncoding은 매우 직관적이고 모든 범주형 자료에서 활용가능합니다. 하지만 차원이 피쳐의 수만큼 증가한다는 커다란 단점이 있습니다. 따라서 가지고 있는 샘플 수가 많다면, 필요한 연산량과 메모리가 기하급수적으로 증가할 수 있습니다. 원핫인코딩 때문에 GCP를 사용한다면 여간 불편할 일일 뿐 아니라, GCP를 사용해도 데이터의 크기가 너무 크기 때문에 불편합니다. 그리고 무엇보다 차원의 저주라는 문제에 봉착할 확률이 높아집니다.1 여러 해결방법이 있겠지만, N진법으로 표현하는 것도 그 중 하나입니다. 이를 BaseN Encoding이라고 하며, 그 중에서 N=2인 Binary Encoding이 가장 대표적입니다. 오늘은 이 두 방식을 소개합니다.
category_encoders
Binary와 BaseN 인코딩 모두 sklearn의 Categorical Encoding Methods 중 하나입니다. 이는 범주형 자료에 대한 인코딩을 전문적으로 다루기 때문에 앞선 포스팅에서 주로 다루었던, sklearn 기본 패키지 (sklearn.preprocessing) 보다 뛰어난 장점이 많습니다. 먼저 sklearn.preprocessing는 array형태로 값을 반환하고, 설사 이를 DataFrame으로 반환한다고 해도 컬럼의 이름이 모두 없어진 상태입니다. 이 때문에 DataFrame으로 만들더라도 0과 1로만 이루어진 결과값을 만나게 됩니다. 이에 반해 category_encoders는 DataFrame으로 결과를 반환할 뿐아니라, 컬럼에 각각 원래의 변수이름이 표현되기 때문에 편리합니다.2
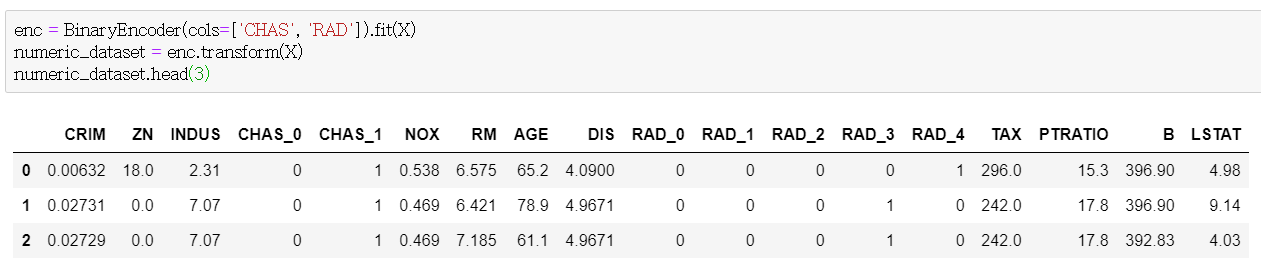
예를 들어, 아래 사진은 범주형 자료 (CHAS, RAD) 를 binary로 바꾼 모습입니다. 별다른 코드 없이도 알아서 DatFrame으로 바꿔줄 뿐 아니라 컬럼 이름까지 get_dummies와 유사하게 보여줍니다. 물론 원핫인코딩처럼 각 컬럼이 특정한 의미를 갖는다고 말할수는 없어집니다. 단순히 어느 범주형 자료를 가공한 것인지를 표현한다고 할 수 있습니다.
추가적으로 sklearn.preprocessing과 비교하여 인풋으로 받는 type은 다음과 같이 구별됩니다.
1
2
1. sklearn.preprocessing : DataFrame, (-1, 1) 꼴의 array
2. category_encoders : DataFrame, Series
옵션도 다양할 뿐 아니라 앞으로 소개할 다양한 인코딩 기법들은 이 method로 작업하기 때문에 사용법을 익혀두는 것이 유용합니다. 먼저 아래처럼 라이브러리를 설치합니다.
1
2
pip install category_encoders
import category_encoders as ce
BinaryEncoder
먼저 2진법으로 표현하는 것의 장점을 간략하게 말씀드리려고 합니다. 평소에 원핫으로 인코딩을 한다는 것은, 완전히 맞는 말은 아니지만 1진법으로 표현하는 것과 유사합니다. 1진법이란, 흔히 개표를 할 때 바를 정(正)자를 써서 득표수를 쓰는 것을 의미합니다. 이 경우, 득표수만큼 획순을 더해가게 되는데, 원핫인코딩도 사실 같은 논리입니다. 다만 피쳐의 갯수만큼 벡터의 길이가 늘어납니다.
반면 2진법은 각 자릿수마다 0과 1 두가지 숫자로 표현합니다. 예를 들어, 100은 1100100이 됩니다. 만약 100가지의 피쳐를 가지는 범주형 변수를 원핫인코딩을 한다거나, 이를 1진법으로 표현하기 위해서는 100차원의 벡터 혹은 100번의 획순이 필요한 것과 비교하면 단 7자리로 표현이 가능하니 엄청난 차원축소라고 할 수 있습니다. 따라서 원핫인코딩이 가지는 메모리 부족3과 차원의 저주도 꽤나 잘 해결할 수 있습니다. 두 인코딩 기법의 차이와 관련해서는 글 가장 아래 참고문헌에서 확인하실 수 있습니다.
구체적인 과정은 아래와 같습니다.
1
2
3
1. numeric value로 바꿔주기
2. 이진법 숫자로 바꿔주기
3. 각 자릿수에 맞추어 컬럼을 만들어주기
처음에 numeric value로 바꿔줄 때는,
Ordinal Encoder를 사용합니다. 여러 이유가 있겠지만, Label 인코딩이 0부터 시작하는 반면, Ordinal 인코딩은 1부터 시작하기 때문에 그렇습니다.
코딩은 다음과 같이 해주면 됩니다.
BinaryEncoder 불러오기
1
2
3
4
from category_encoders import *
UserName = BinaryEncoder(cols = ['RAD'], drop_invariant=True)
UserName
자신이 원하는 옵션을 결정하는 곳입니다. 다양한 기능을 사용할 수 있지만, 대다수 default로 잘 설정이 되어있습니다. 위에 처럼만 코딩을 해주어도, 새로운 변수를 0 벡터꼴로 바꿔주기 때문에 차원변화없이 문제를 잘 해결할 수 있습니다. 참고로, drop_invariant는 모두 하나의 값으로만 이루어진 컬럼을 제거하는 기능을 수행합니다.
fit_transform
fit과 transform의 기능을 합친 것입니다. 인코딩을 원하는 데이터를 집어넣는 첫 단계이며, 결과가 위에서 생성한 instance에 저장이 됩니다. 따라서 새로운 값을 마주할 때 차원을 유지하거나, 원래 값이 궁금할 때에 손쉽게 확인할 수 있습니다.
1
UserName.fit_transform(UserData)
transform, inverse_transform
transform은 앞서 인코딩한 방식에 새로운 데이터셋을 집어넣어 같은 방식으로 변환을 해줍니다. 이때 여러 새로운 피쳐를 집어넣어도 모두 0으로 이루어진 컬럼으로 값을 반환합니다. 원래 데이터가 궁금하다면 inverse_transform을 해주면 됩니다. 새로운 데이터셋에 해당하는 값들은 NaN으로 반환합니다.
추가로 이 역시 make_column_transfer과 함께 쓰여서 하나의 데이터 안에서 일부분에만 작업을 해주는 것이 가능합니다. 자세한 예시는 저의 깃헙을 참고하시면 됩니다.
BaseN
앞에서 Binary는 BaseN 인코딩에서 N을 2로 설정한 것과 동일함을 이야기했습니다. 조금 더 확장하면, 다음과 같을 것입니다.
1
2
3
4
1. N = 1 : OneHot 인코딩
2. N = 2 : Binary 인코딩
3. ...
4. N = N : Ordinal 인코딩
N = 1일 때는 완벽하게 OneHot 인코딩과 같지는 않지만, 사실상 같다고 봐도 무방합니다.
앞에서 2진법으로 표현하여 차원의 수를 대폭 줄였다면, N을 더욱 크게 해서 더욱 간결하게 차원을 축소한다면 좋을 것이라고 생각할지 모릅니다. 하지만 실제로 2진법 이외의 인코딩 기법은 많이 사용하지 않습니다. 몇 가지 이유를 추측할 수 있을 것입니다. 첫째, 3진법 이상부터는 0과 1이 아닌 더 큰 숫자가 등장합니다. 이렇게 되면, 하나의 컬럼에 대소관계가 점차 많이 드러나게 됩니다. 이 경우, Ordinal한 데이터가 아님에도 그렇게 해석될 여지가 생겨버립니다. 둘째, 이미 2진법으로도 충분히 차원을 축소할 수 있습니다. 앞에서 말했듯이 100자리의 원핫인코딩은 단 7자리로 대체가 가능합니다.
따라서 실제로 BaseN을 사용하는 사례는 매우 적습니다. 다만 Grid 서치처럼 최적 변수를 찾기 위해서 간혹 사용하는 것처럼 보입니다. 자세한 사례는 이 곳에서 확인하실 수 있습니다.