IGAWorks 공모전이 제공하는 파일에는 까다로운 자연어 처리가 필요합니다.
본 글에서는 클러스터링을 진행하기 위해서 제가 진행했던 전처리 과정을 소개드립니다.
다만, 보안과 저작권의 문제로 일부 변형한 데이터를 사용했습니다.
1
2
3
import pandas as pd
aud = pd.read_csv("data/[label] aud_wo_install&house.csv")
aud.head(3)
| device_ifa | age | gender | marry | cate_code | |
|---|---|---|---|---|---|
| 0 | 1648210 | 6 | M | M | 20008:5,21001:1,01003:2,14004:2,06009:2,03003:... |
| 1 | 1885479 | 6 | F | M | 09001:1,13002:3,01003:1,16004:3,18002:1,21007:... |
| 2 | 1289369 | 7 | F | M | 16002:5,19001:4,04011:1,p0011:1,18004:3,p0010:... |
1
2
3
4
5
def short(x):
return x[1::2]
def long(x):
return x[::2]
1
2
3
4
aud["cc_list"] = aud["cate_code"].str.findall(r"[\w']+")
aud["short"] = aud["cc_list"].apply(short)
aud["long"] = aud["cc_list"].apply(long)
aud['counts'] = aud['long'].str.len()
1
2
import seaborn as sns
import matplotlib.pyplot as plt
1
2
3
4
5
6
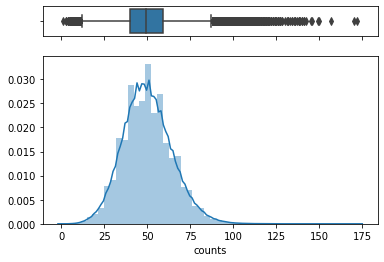
f, (ax_box, ax_hist) = plt.subplots(2, sharex=True, gridspec_kw={"height_ratios": (.15, .85)})
sns.boxplot(aud.counts, ax=ax_box)
sns.distplot(aud.counts, ax=ax_hist)
ax_box.set(xlabel='')
1
2
3
4
5
6
7
from collections import Counter
from itertools import chain
vc = pd.Series(Counter(chain(*aud.long))).sort_index().rename_axis('value').reset_index(name='counts')
vc = vc.sort_values(by =['counts'] , ascending = False)
vc['ratio'] = vc['counts'] / len(aud)
vc.head(3)
| value | counts | ratio | |
|---|---|---|---|
| 129 | 14004 | 812687 | 0.999886 |
| 179 | 20008 | 810422 | 0.997099 |
| 133 | 15003 | 810370 | 0.997035 |
1
2
3
4
5
6
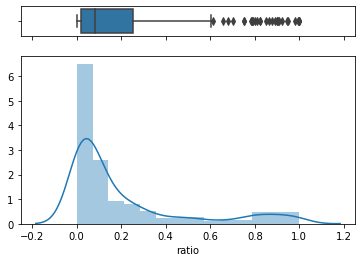
f, (ax_box, ax_hist) = plt.subplots(2, sharex=True, gridspec_kw={"height_ratios": (.15, .85)})
sns.boxplot(vc.ratio, ax=ax_box)
sns.distplot(vc.ratio, ax=ax_hist)
ax_box.set(xlabel='')
1
2
3
4
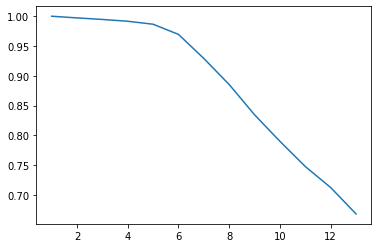
criteria = []
for i in range(13) :
criteria.append(vc.head(i+1).value.tolist())
1
2
3
4
5
6
import matplotlib.pyplot as plt
x = list(range(1,14))
y = pct
plt.plot(x, y)
plt.show()
1
2
3
4
5
6
7
8
9
good = criteria[-1]
trash = list(set(vc.value) - set(criteria[-1]))
Li = []
for i in range(len(aud)) :
tmp_dict = dict(sorted(dict(zip(aud['long'][i], aud['short'][i])).items()))
[tmp_dict.pop(key, None) for key in trash]
Li.append(tmp_dict)
- 두 개의 리스트로부터 dict 도출
- 도출한 dict을 알파벳 순서로 sort
- 이를 list에 추가함으로써 저장
1
res = pd.DataFrame.from_records(Li, index = aud.device_ifa.values)
1
res.head()
| 06001 | 06006 | 06009 | 14004 | 14005 | 15001 | 15003 | 15004 | 19001 | 19003 | 20008 | 21007 | 23005 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1648210 | 2 | 5 | 2 | 2 | 3 | 4 | 3 | 1 | 2 | 5 | 5 | 3 | 1 |
| 1885479 | 3 | 2 | 3 | 2 | 1 | 1 | 2 | 3 | 2 | 2 | 2 | 4 | NaN |
| 1289369 | 5 | 2 | 3 | 3 | 2 | NaN | 4 | 3 | 4 | 1 | 4 | 3 | 5 |
| 1415766 | 2 | 1 | 1 | 3 | 4 | 1 | 4 | 3 | 2 | 2 | 3 | 1 | 5 |
| 1928794 | 4 | 3 | 4 | 1 | 1 | 2 | 1 | 2 | 1 | 5 | 3 | 3 | 5 |